BOJ 34507 Scary Subsequences
sorohue가 PS하는 블로그
문제 링크입니다.
문제 요약
4개의 문자 $a$, $b$, $c$, $d$로만 이루어진 세 문자열 $x$, $y$, $z$를 모두 부분수열1로 포함하는 문자열 $s$에 대해, $x$, $y$, $z$ 중 어느 것의 부분수열도 아닌 $s$의 부분수열의 최소 길이를 구하세요.
문제 환원하기
$s$는 $x$, $y$, $z$를 각각 부분수열로 가지므로 $x$, $y$, $z$의 모든 부분수열 역시 부분수열로 갖습니다. 이 부분수열의 집합을 $xyz$라 합시다. 이러한 부분수열을 제외한 다른 부분수열을 찾는 것이 문제의 목적이기 때문에, $s$의 모든 부분수열 집합 $S$에서 해당 부분수열을 제거한 집합 $T$를 고려합시다.
$T$의 최소 길이 원소를 찾기 위해 원소를 길이 별로 분류합니다. $T$에 길이가 $i$인 원소가 존재하려면 $S$의 길이 $i$인 원소 중 $xyz$의 원소가 아닌 것이 존재해야 합니다. 이때 $xyz \subset S$ 이므로 이러한 원소의 개수는 단순히 $S$의 길이 $i$인 원소 개수에서 $xyz$의 길이 $i$인 원소 개수를 빼는 것으로 얻을 수 있습니다.
즉 우리는 $xyz$와 $S$에서 각 길이마다 원소의 개수를 카운팅하는 것으로 문제를 해결할 수 있습니다!
$S$ 카운팅
하나의 문자열 $s$의 부분수열 집합 $S$의 길이 별 원소 개수를 카운팅해 봅시다.
같은 부분수열이 중복되어 카운팅되는 것을 방지하기 위해, 항상 가능한 모든 부분수열 중 그 인덱스가 사전순 최소인 것만을 세기로 합시다. 이를 위해서, 각 인덱스마다 글자 별로 가장 가까운 다음 인덱스를 ${\cal O}(\vert s \vert)$에 전처리할 수 있습니다.
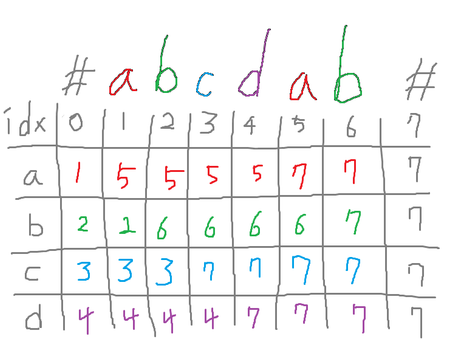
그러면 부분수열의 개수를 문자열의 맨 앞에서 DAG를 따라 이동하는 경로의 수처럼 생각할 수 있고 이는 간단한 DP로 계산 가능합니다. 우리는 각 길이 별로 부분수열의 개수를 세어야 하기 때문에, 다음과 같은 DP를 정의할 수 있습니다.
- $D[i][j] :=$ 마지막에 $i$번째 문자가 오는 길이 $j$의 부분수열 개수
- $D[0][0] = 1$
DP 테이블의 각 칸을 방문하면서 글자 별로 간선을 따라 다음 칸에 값을 던져주는 방식으로 전파가 진행됩니다. 글자의 종류는 4가지로 정해져 있으니 모든 길이에 대한 부분수열 개수를 ${\cal O}(\vert s \vert^2)$에 계산할 수 있습니다.
일반성을 잃지 않고 $\vert x \vert = \max( \vert x \vert, \vert y \vert, \vert z \vert )$라고 하면, 사실상 길이가 $\vert x \vert+1$ 이상인 부분수열의 개수는 알 필요가 없습니다. 길이가 $\vert x \vert+1$인 부분수열은 입력 조건에 의해 존재하고, 이는 $x$, $y$, $z$ 중 어느 것에도 포함되지 않습니다. 따라서 길이가 $\vert x \vert$ 이하인 부분수열만 찾으면 되고 시간복잡도를 ${\cal O}(\vert x \vert \vert s \vert)$로 줄일 수 있습니다.
$xyz$ 카운팅
세 문자열 $x$, $y$, $z$ 중 어느 하나에라도 부분수열로 포함되는 문자열 집합 $xyz$의 길이별 원소 개수를 카운팅해 봅시다.
기본적으로는 $S$에서 카운팅을 하는 방법과 동일합니다. $x$, $y$, $z$에서 각각 DAG를 만들어 주고 DP의 상태를 다음과 같이 정의합니다.
- $D[i][j][k][l] :=$ $x$의 $i$번째 문자, $y$의 $j$번째 문자, $z$의 $k$번째 문자가 각각 마지막 문자에 해당하는 길이 $l$의 부분수열 개수
- $D[0][0][0][0] = 0$
같은 방식으로 전파를 진행하면 ${\cal O}( \vert x \vert^4)$에 DP 테이블을 채우고 길이 별로 원소 개수를 셀 수 있습니다.
이를 전처리한 뒤 쿼리마다 $S$에서 카운팅하는 과정을 거치면 총 시간 복잡도 ${\cal O}( \vert x \vert^4 + \vert x \vert \sum_i \vert s_i \vert )$에 문제를 해결할 수 있습니다.
코드
길이 별 원소 개수의 합이 64비트 정수 범위를 넘을 수 있음에 유의해 주세요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
#include<bits/stdc++.h>
using namespace std;
using ll = long long;
using i128 = __int128;
using pii = pair<int, int>;
using pll = pair<ll, ll>;
array<int, 4> xnxt[66], ynxt[66], znxt[66];
string x, y, z;
ll d[66][66][66][66]; i128 xyz[66]; //xlast, ylast, zlast, len
ll scnt[303030][66]; i128 sum[66]; vector<array<int, 4>> snxt;
int main(){
cin.tie(0);cout.tie(0);ios::sync_with_stdio(false);
cin >> x >> y >> z; d[0][0][0][0] = 1;
xnxt[x.size()] = xnxt[x.size()+1] = {x.size()+1, x.size()+1, x.size()+1, x.size()+1};
ynxt[y.size()] = ynxt[y.size()+1] = {y.size()+1, y.size()+1, y.size()+1, y.size()+1};
znxt[z.size()] = znxt[z.size()+1] = {z.size()+1, z.size()+1, z.size()+1, z.size()+1};
for(int i = x.size()-1; i >= 0; i--) xnxt[i] = xnxt[i+1], xnxt[i][x[i]-'a'] = i+1;
for(int i = y.size()-1; i >= 0; i--) ynxt[i] = ynxt[i+1], ynxt[i][y[i]-'a'] = i+1;
for(int i = z.size()-1; i >= 0; i--) znxt[i] = znxt[i+1], znxt[i][z[i]-'a'] = i+1;
for(int xi = 0; xi <= x.size()+1; xi++) for(int yi = 0; yi <= y.size()+1; yi++) for(int zi = 0; zi <= z.size()+1; zi++){
if(xi == x.size()+1 && yi == y.size()+1 && zi == z.size()+1) break;
for(int nw = 0; nw < 4; nw++){
int nxi = xnxt[xi][nw], nyi = ynxt[yi][nw], nzi = znxt[zi][nw];
if(nxi == x.size()+1 && nyi == y.size()+1 && nzi == z.size()+1) continue;
for(int len = 0; len <= 60; len++) d[nxi][nyi][nzi][len+1] += d[xi][yi][zi][len];
}
for(int len = 0; len <= 60; len++) xyz[len] += d[xi][yi][zi][len];
}
int q; cin >> q; while(q--){
string s; cin >> s; int ans = max({x.size(), y.size(), z.size()})+1; for(int i = 0; i < ans; i++) sum[i] = 0;
snxt.clear(); snxt.resize(s.size()+2); snxt[s.size()] = snxt[s.size()+1] = {s.size()+1, s.size()+1, s.size()+1, s.size()+1};
for(int i = s.size()-1; i >= 0; i--) snxt[i] = snxt[i+1], snxt[i][s[i]-'a'] = i+1;
for(int i = 0; i <= s.size()+1; i++) for(int j = 0; j <= 60; j++) scnt[i][j] = 0; scnt[0][0] = 1;
for(int i = 0; i <= s.size(); i++){
for(int nw = 0; nw < 4; nw++) if(snxt[i][nw] != s.size()+1) for(int len = 0; len <= 60; len++) scnt[snxt[i][nw]][len+1] += scnt[i][len];
for(int len = 0; len <= 60; len++) sum[len] += scnt[i][len];
}
for(int i = ans-1; i >= 1; i--) if(sum[i] > xyz[i]) ans = i; cout << ans << '\n';
}
}
어떤 문자열의 부분수열(subsequence)은 그 문자열에서 0개 이상의 문자를 제거한 뒤 남은 문자를 순서를 바꾸지 않고 이어붙인 문자열입니다. ↩︎